")
")


By Battista Biggio and Matteo Mauri
Heading image by Geralt, Pixabay
We know, this is an ill-posed question. It cannot be shown that a system is secure, if not with respect to a precise attack model and under very specific assumptions. It is instead possible to demonstrate, in a much clearer way, when a system is vulnerable, and this is what we will try to do in this article, in relation to Artificial Intelligence (AI) systems.
It is quite known that the security of a system depends solely on the strength of its weakest link. AI is now pervasive and integrated in a transparent way in many different application scenarios and deployed systems. From the viewpoint of computer security, it is therefore legitimate to ask ourselves if AI algorithms themselves do not introduce novel vulnerabilities in such systems, potentially becoming the weakest link in the corresponding security chain.
In this article, we will try to shed light on this problem, discussing the main attack vectors that can be used to confound an AI system in different application contexts, and the more promising countermeasures that can mitigate these risks.
The AI revolution in modern applications
AI has been defined the new electricity. Andrew Ng, Adjunct Professor at Stanford University, co-founder of Coursera and Baidu's chief scientist, along with many other experts, argues that AI algorithms are paving the way for a new industrial revolution.
AI and deep learning. At this point it is necessary to clarify the meaning of AI, since the whole AI research area includes many different learning paradigms. In this context, we refer to the modern definition of AI, which mostly refers to deep learning algorithms. This category of algorithms belongs to the subset of AI algorithms known as machine learning algorithms. In particular, the definition “deep learning” derives from the specific structure of these algorithms, as they are based on deep neural networks characterized by many layers or levels, connected in a sequential way.
The recognition phase. If one considers each level of a deep network as a filtering operation applied to its input, the overall architecture amounts to applying a certain sequence of filters to the input data (for example, an image representing a given object).
Each level, or filter, is characterized by a set of neurons that are activated only when they perceive a given pattern at their input. This mechanism, in principle, allows the network to gradually compress the information contained in the input image by building more abstract representations of the object to be recognized, up to correctly assign it to its class. This process is conceptually represented in Fig. 1.
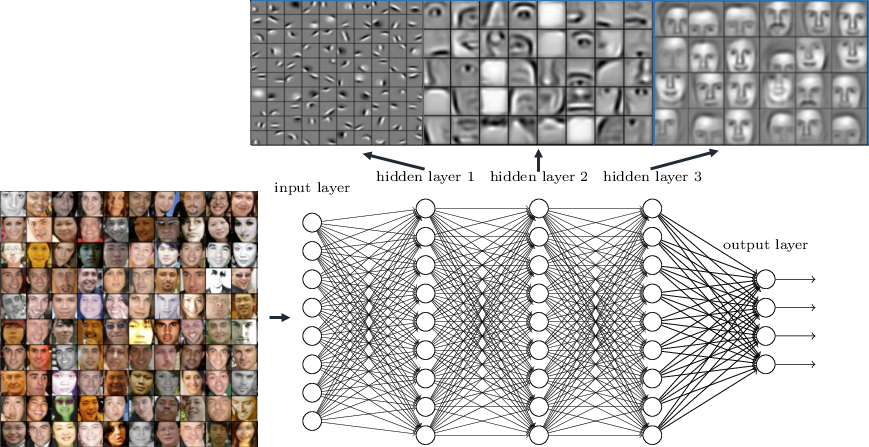
Fig. 1. Example of representations learned at different levels by a deep neural network for face recognition. The picture shows how the learned representations range from low-level representations (which detect edges, textures, etc.) to high-level ones (which recognize the user faces). Source: https://www.rsipvision.com/exploring-deep-learning/
The training phase. The complexity of these algorithms clearly lies in automatically constructing these representations, and in understanding how to construct the sequence of filtering operations to be applied to the input data. For this purpose, these algorithms require a training phase, during which the system is trained with various images of objects that it must be able to recognize, together with their class label.
During this phase, the neural network tries to predict the correct class of the training objects and, if wrong, it adjusts its parameters to improve towards the correct prediction (which amounts to varying the way each neuron responds to certain patterns observed in the data).
At the end of this process, the algorithm has learned to distinguish objects of different classes based on statistical correlations, and to recognize particular patterns associated with the different types of objects present in the training data.
It is easy to see how this mechanism is profoundly different from the complex learning process of humans: just to name one main difference, we do not need millions of labeled examples to recognize objects and the world around us.
Super-human performances. Given the enormous availability of data that can be gathered today and the impressive computing power of new computers and cloud architectures, in some specific application scenarios, deep learning has even shown to outperform human abilities. A very popular example where algorithms have surpassed human performance is represented by ImageNet. ImageNet is a database containing more than 14 million images and it has been used for several years as a basis for the competition “ImageNet Large Scale Visual Recognition Challenge (ILSVRC)”. In this competition, different algorithms compete to correctly recognize objects belonging to 1,000 different classes. Figure 2 shows the progress of the fraction of incorrect recognitions in this competition over the years. It can easily be seen that in 2015, the best algorithm of the competition achieved a higher accuracy than the average one reported by humans to solve the same problem.
To be intellectually honest, we must say that some images are clearly ambiguous and we ourselves would be confused in evaluating which object they contain. However, it has been quite surprising to see that an automatic algorithm can exhibit such performances on a very complicated task like that posed by the ImageNet competition.
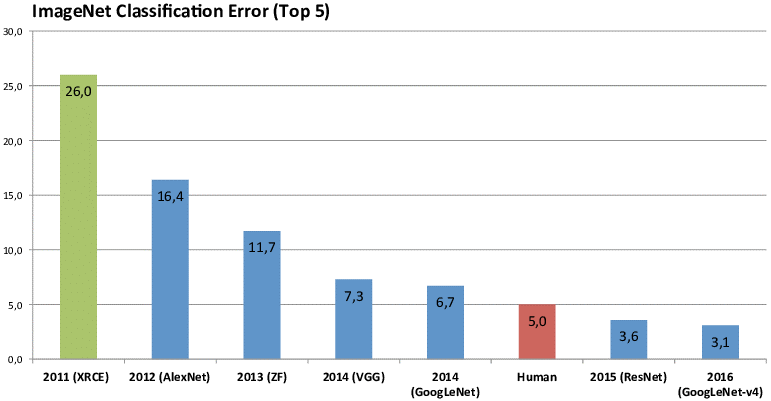
Fig. 2. Progress of the percentage of incorrect recognition of objects in the ILSVRC competition over the years.
Source: https://www.researchgate.net/publication/324476862_Survey_of_neural_networks_in_autonomous_driving
The ImageNet “case”, however, is not the only one that registered the success of AI. Another emblematic case, and perhaps even more popular, is represented by videogames and strategy games. AI algorithms have long proved to be much better than humans at playing chess; but lately they are proving superior even in much more complex games and video games, including first-person shooter games. Recently, DeepMind has shown that their AI algorithm can independently learn to defeat highly skilled human players in a complex video game like StarCraft II [1]. Here too, the strength of their algorithm, called AlphaStar, lies in the possibility of observing a lot of (labeled) data. Specifically, the algorithm can potentially play endless games, and continuously analyze their output. In this manner, through reinforcement learning, it is possible to train the AI algorithm to improve its performances error after error, and game after game.
Moreover, there is a considerable number of applications where the deep neural networks have established new performance standards, from the segmentation and recognition of objects in videos [2], to the diagnosis of particular diseases from medical images, up to speech recognition (think, for example, to the voice assistants available today on our mobile phones or as home helpers).
Even in the computer security field, AI is now pervasively used to fight cyberattacks. For example, AI algorithms are used to detect domains and malicious websites perpetrating various scams towards their end users (phishing pages or illegal pharmacies), and to detect intrusions in corporate networks (through behavior profiling of the company employees). Similar algorithms are also used in the context of physical security; for instance, to help video-surveillance operators who monitor critical areas.
Given what we have discussed so far, it may seem that AI and, in particular, deep learning algorithms are the new Eldorado, the panacea to all ills. But we all know that all that glitters is not gold...
Can AI be deceived?
In fact, certain manipulations of the data supplied as input to these algorithms, could confuse them, in some cases, even blatantly. The most glaring and popular adversarial example is perhaps the one reported in "Intriguing properties of neural networks", published by the researchers of Google Brain in 2013. This example shows how an image representing a school bus, modified with an adversarial perturbation imperceptible to the human eye, is erroneously recognized as an ostrich by one of those AI algorithms that recorded a super-human performance on ImageNet.
After this discovery, the scientific community has started to investigate similar attacks in other domains, envisioning attacks against face recognition systems for biometric and forensic applications (Fig. 3), against traffic-sign recognition systems for self-driving cars (Fig. 4), and even against voice assistants, showing how these can be confused by an audio noise almost imperceptible to the human ear [3].

Fig. 3. In the article "Accessorize to a crime: real and stealthy attacks on state-of-the-art face recognition" published in 2016, some researchers have shown that, by wearing such bizarre eyeglass frames, one can be misrecognized by the considered AI algorithm as the famous actress Milla Jovovich.

Fig. 4. In the article "Robust Physical-World Attacks on Deep Learning Models" published in 2018, some researchers have shown how to deceive the traffic-sign recognition system of a self-driving car by simply placing stickers on a stop signal. In front of this manipulation, the algorithm misclassifies the stop sign as a speed-limit sign.
As already said, the year 2013 has been an important year for this research field. However, to say the truth, the problem of (in)security of AI algorithms had been largely known before to researchers in computer security. In particular, it was clear from the beginning that AI algorithms deployed in security-sensitive settings, sooner or later, had to deal with intelligent and adaptive attackers, especially since the latter have a clear motivation and/or financial incentive to deceive them. As early as 2004, AI algorithms for email spam detection were already known to be vulnerable to adversarial attacks in which spammers manipulate the content of spam emails to bypass detection without compromising the readability of spam messages for humans. And, more recently (2012-2013), attack algorithms against neural networks were already working with success [4]. In particular, the scenario described above only identifies a specific vulnerability of AI algorithms. This scenario, also known as evasion, consists of manipulating the input data to have it misclassified by a previously-trained (and deployed) algorithm.
In a different scenario, known as poisoning, the attacker can contaminate training data to prevent the system from working properly, causing a denial of service for legitimate users (for example, preventing an employee from properly authenticating to corporate services), or by setting up backdoors in the system (in order to guarantee access to a protected system, or causing system failure when the input data activates the backdoor).
There are also attacks that aim to violate the privacy of the AI system or of its users. It has been shown that it is possible to reconstruct the image of a user's face from a face recognition system by repeatedly observing the output of the system on a particular sequence of images (Fig. 5). This means that, if the system is available as an online service, an attacker may violate the privacy of its users by iteratively querying the service. Using a similar mechanism, it is even possible to "steal" the AI model, by building a copy of it – and this could be a problem for companies that offer web-based paid services. Or again, it could be problematic if an attacker succeeds in replicating the functioning of an online anti-virus system, as this may facilitate the task of evading detection.

Fig. 5. Reconstruction of a user's face image, obtained through a series of requests sent to the face recognition system: the original image is shown on the left, while the reconstructed image is shown on the right. Source: "Model inversion attacks that exploit confidence information and basic countermeasures", 2015.
Why is AI vulnerable? And what are the possible countermeasures to make it safer?
At first glance, these AI vulnerabilities may seem quite incredible, given the super-human performance of the aforementioned algorithms in some application areas. However, the question is much less surprising if we consider how these algorithms "learn" from data. As discussed above, AI algorithms learn from large volumes of labeled data (in the most common paradigm of supervised learning), according to an optimization process that gradually forces the algorithm to correctly learn the label assigned to each training sample, by adjusting its internal parameters. These algorithms are therefore profoundly influenced by the data used for their training and by how the optimization process that simulates learning is shaped.
It is clear that, if an attacker has the chance to manipulate these data samples and exploit the peculiarities of the optimization process, AI algorithms can be successfully compromised, even in different and complementary ways, as highlighted above; for example, introducing spurious correlations in the data, manipulating the object to be recognized, or even directly altering the training data.
In concrete, the vulnerability of these algorithms is an inherent characteristic of their learning mechanism and of their underlying design process; none of the most popular and widely used AI algorithms has been indeed designed to correctly account for potential, specific adversarial transformations of the input data.
Recently, the scientific community has spent a great effort in designing countermeasures to tackle this challenging problem. While many proposed countermeasures have been shown to be ineffective, some have achieved promising results. In particular, there are more or less mature and effective solutions to mitigate the problem of training data contamination (also known as poisoning) and to preserve the privacy of AI systems, while the problem of countering evasion attacks (aimed at confusing the AI system during classification) remains largely open.
The most promising solutions to the various types of attack, almost always have a common denominator: a more or less explicit modeling of the potential data manipulations that the system can encounter. In essence, the best solutions provide the AI system with additional knowledge about how an attacker can behave; knowledge which is not (and cannot be) typically available in the training data. This is quite clear in the case of cyberattacks, where it is not possible to assume that a comprehensive and representative collection of all potential attacks, including zero-day ones, is available.
Then, how should we model attacks to proactively improve the security of AI systems? How should we integrate these models into the learning process, to make it more secure by design? These are still complex problems and the challenge remains thus open. Some researchers imagine that, in the future, AI algorithms will compete against each other by emulating a war game between the attacker and the defender; others argue that AI won’t have enough autonomy and that the experience of the human expert will remain essential to really improve the safety of such systems. The answer, as typically happens, could be that there’s no free lunch - most likely, there is no general solution to the problem, but different solutions will have to be studied and tailored to the different application contexts.
Acknowledgments. An Italian version of this article has been published in [5]. The authors thank “Associazione Italiana per la Sicurezza Informatica” for permission to reuse the contents.
[1] https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii
[2] An example is shown in the video at this link: https://www.youtube.com/watch?v=dYVH3p-RuPQ
[3] Some examples are available here: https://nicholas.carlini.com/code/audio_adversarial_examples
[4] More details in our article “Wild Patterns: Ten Years after the Rise of Adversarial Machine Learning”, published in 2018
[5] B. Biggio, L'Intelligenza Artificiale è Sicura?, Rapporto Clusit 2019 sulla Sicurezza ICT in Italia, 2019 (in Italian).


