")
")


by Fabio Roli and Matteo Mauri
Heading image by geralt on Pixabay
In the first part of this article “Artificial Intelligence: past, present and future. Part I - Short history of Artificial Intelligence”, previously published in this blog, we tried to unpack the "suitcase" of Artificial Intelligence. Now we will discuss the "good", "ugly" and "bad" aspects inside this “suitcase”. As the reader will immediately notice, the title is a small tribute to the famous movie by Sergio Leone. We are not the first to use this leitmotiv to talk about Artificial Intelligence. AI certainly has "good", "ugly" and "bad" aspects; highlighting these aspects can help to understand what is Artificial Intelligence today. Always bearing in mind that, as in the case of the three characters of the movie, the good, the bad and the ugly cannot be clearly separated.
The good
In the following, we illustrate three positive aspects of AI for economic and social development.
AI is good because it works (if properly used: AI can do much, but not everything...)
As Rodney Brooks (MIT professor and founder of Rethink Robotics and iRobot), described well in his article on the "seven deadly sins" of the AI, currently there is a lot of confusion around what AI can do and what AI can’t do [1]. Many people oscillate between unrealistic expectations and unmotivated mistrust. The confusion is often increased by advertising messages that define products that use traditional technologies in a slightly different way as "intelligent".
The underlying problem is a lack of understanding of how AI works and what it can do. Today AI is basically "machine learning" combined with great computational power (for storing and processing data); for this reason, AI is able to "generalize” from known cases, seen during the learning phase, to new cases on which it will operate.
We can train AI algorithms with millions of object images and this makes algorithms able to recognize the same types of objects in new images, with a precision that has recently surpassed that of the human being. But the good performances, the so called "generalization" capability of the current AI, depends strongly on the assumption that the "future", the new cases to be recognized, is not too different from the "past", the cases already learned. Between the future cases never seen and the past ones there must exist a probabilistic relationship that guarantees the so-called "stationarity" of the data; difficult technical question, but well known from the practical point of view in the field of computer security: the attacks "never seen before", without any relation to the past ones (the "unknown unknowns" by Donald Rumsfeld), cannot be foreseen, at least not with the current AI. The other important element for the good operation of today's AI is the "quality" of the data provided during the training phase, when the algorithm learns. The issue is technically complex but simple to guess: errors, of various nature, present in the training data can cause more or less serious errors for the operation of our AI. If I train an algorithm to discriminate between legitimate and malicious applications ("malware") but I show them above all examples where malware is a compressed file (a zip), the algorithm will erroneously learn that all compressed files are malicious. If I train an algorithm to predict the likelihood of a person committing a crime but only show the algorithm examples where criminals are colored people the algorithm will learn that all colored people have a high probability of committing a crime. It would seem trivial to avoid these errors, but this is not the case when the training data is millions and come from sources disparate from the Internet. In conclusion, today's IA is good because it works, in some cases even better than human beings, but to make it works it is necessary to understand well the hypotheses of good operation.
AI is good because it is useful
Assuming that AI works if we use it for what it can do, the next question is obviously: what AI can do is also useful? The answer is positive: there are many applications with great added value that satisfy the hypothesis of good operation of AI. To fully understand the practical usefulness of AI, it is important to understand that, to be useful, AI does not necessarily have to work without a man in the loop; futuristic intelligent systems that are completely “autonomous” are not needed: it is more than sufficient that AI can replace the man in some parts of a task ("automation") or that AI can collaborate with the man to perform better a certain task, or to complete it with less effort ("human-machine teaming") [2]. AI did not need to become completely "autonomous" to be very useful in the automotive sector. ADAS systems (Advanced Driver Assistance Systems) are now on board of many vehicles and they use AI technologies developed over the past decades to assist the driver in certain tasks, such as braking to avoid collisions with a pedestrian. In some applications, AI can be very useful because it is complementary to humans. In a recent medical study for the diagnosis of cancer, it was shown that an AI system, designed to co-work with a radiologist, had much better performance than AI alone or the radiologist alone. Each was complementary to the other [3].
AI is good for a “moon shot” approach
In retrospect, the approach used by the AI fathers during the famous Dartmouth workshop, August 1955, might seem an example of what we now call the "moon shot” approach [4]. The project that gave its name to the "moon shot" approach was crowned with success: on July 21st 1969 a man walked on the moon. The original AI project did not lead where the founding fathers thought: we have no robots with human intelligence; but we have Alexa, and one of the authors of this article finally takes the taxi in China without leaflets with the Chinese translation of the hotel name [5], and we have many other concrete and useful results.
History can repeat even today. AI can really trigger "moon shot" projects at the level of individual countries and at an supranational level. Some countries have already launched their "moon shot" projects for AI. In 2017, China announced its strategic plan for world supremacy in AI, with more than 10 trillion RMB of investment. The United States, even without similar strategic plans, maintains activities and investments for AI at very high levels; some unclassified reports say that the Pentagon wants to invest something like 7.4 billion dollars for AI technologies. The European Commission is carrying out a coordinated program on AI [6]. Many other countries have announced their national strategies for AI (Figure 1) [7]. Last but not least, Italy recently created a national AI lab [8].
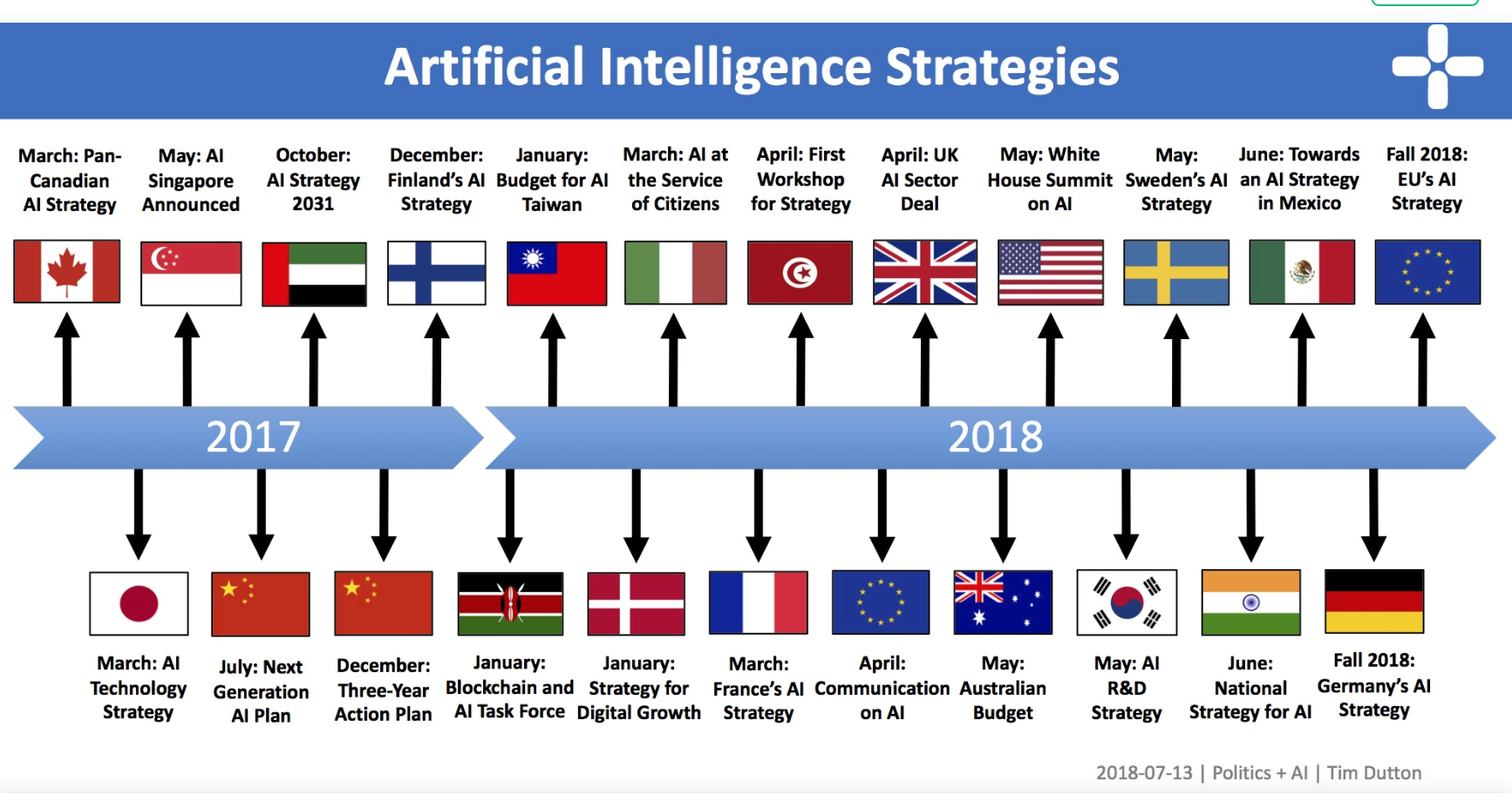
Fig. 1: National strategies for artificial intelligence in the world
The ugly
In the following we briefly discuss two aspects that we consider "ugly", which means extremely critical for the future of AI. In our opinion, they should be treated with extreme care, on pain of another AI "winter" with reduced interest and cut funding.
Can we trust AI?
History teaches that creating "trust" in a technology is fundamental to making it widely used and maximizing its benefits. AI is not an exception. A paradigmatic example is the IBM's "Watson for Oncology": an AI-based technology developed to assist physicians in the treatment of twelve types of cancer [9]. The results of the trial showed that the doctors did not trust the Watson system and used its advice only when it coincided with their opinions, otherwise they tended to think that Watson was wrong. On the other hand, human trust is often based on our understanding of how others think and on our experience of their reliability; we still have little experience with AI and it is often poorly understood by the majority. For these reasons, the European Commission has placed the development of a "Trustworthy AI made in Europe" [10] at the center of its strategy for AI. The objective is to promote the development of a technology that respects the fundamental rights of European citizens and that is technically reliable.
Explainable AI
One of the keys to obtain a "Trustworthy AI" is to make the technology "transparent". The new "deep learning" algorithms are making AI systems always more similar to "black boxes", inscrutable oracles. But the advent of GDPR (in particular Art. 22 among the others), seems to impose a "right to transparency" for the European citizens. Transparency will therefore be the key to build and maintain the citizens' trust. On the transparency topic, research is placing great emphasis under the umbrella of what is called "Explainable AI" [11] [12]. The goal is to create an AI whose decisions and actions are understandable and trustable.
Adversarial Machine Learning
There can be no trust without security. In the 1980s, Machine learning was hailed as the "silver bullet" of security, in particular cybersecurity. The strong link of the chain, able to detect "never seen before" threats that could not be detected with traditional signature-based systems [13]. It was therefore a small shock when the researchers showed that machine learning algorithms could be easily deceived, to the point of causing them recognize a bus for an ostrich (Figure 2). Today the research pays great attention to safety and adversarial machine learning (machine learning in a hostile environment) is one of the most interesting topics. [14].
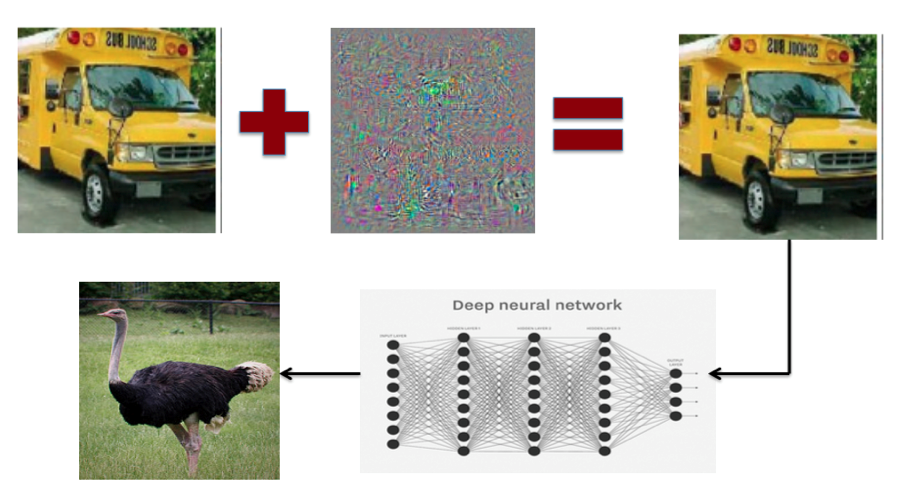
There is no doubt that the future of AI will depend on the outcome of the challenge on "trust" intended as security and transparency.
Myths and wrong expectations
We have already seen it in the 1970s and then again in the 1980s, the lack of understanding about what AI can really do can create wrong expectations, followed by periods of disillusions with reduced interest and drastic cuts in funding. Rodney Brooks has well described the main errors of understanding and wrong perspective. One of the greatest dangers for the future of AI is that many researchers tend to overestimate what AI can do today and underestimate what it can do in the future. We see algorithms that can "tag" a photo with the phrase "person who plays Frisbee" and, because of that, we automatically overestimate what the algorithm can do: we expect it can recognize our face in a photo even after many years. We believe that robots will replace all the bricklayers in 10 years, when it is quite clear that the manual skills of the current robots are still very limited if the work environment is not well known.
The bad
Much has been written about the "bad" aspects, in the sense of dangerous, of AI. The Future of Life Institute believes that AI involves an "existential risk": in other words it is one of the technologies, together with nuclear and biotechnology, which, if poorly governed, could lead to the extinction of the human race [16]. Other authoritative voices are less pessimistic. Rodney Brooks considers it a mistake to worry about the possibility of a "malignant" artificial intelligence in the next hundred years [17]. Although the discussion on the existential risk of AI is important, in the following we will focus on two shorter-term dangers.
"Dual use" of AI
AI is clearly a technology with a "dual use"; there is no doubt that it can be used both for civil and military purposes and, more generally, for beneficial and harmful purposes [18]. Many of the tasks that AI can already automate, have an intrinsic "dual use". Intelligent systems, capable to identify vulnerabilities in software, can be used for both defensive and offensive purposes; a semi-autonomous drone can be used to deliver packages or to transport explosives. In general, the research that aims to increase our understanding of AI, its potential and our control over it, is intrinsically dual-use oriented. It is therefore extremely important that researchers and professionals in general take responsibility for promoting the beneficial uses of AI, while seeking to prevent harmful uses.
AI and manipulation of information
In a recent article Giorgio Giacinto discusses the fundamental role of "social engineering" in the manipulation of information and how it relies on the asymmetry of knowledge and on the technocratic domain: the greater knowledge and technical skills allow an easy manipulation and control of the information [19]. If this is true, then it becomes easy to understand the current and future role of AI in information manipulation. AI can widen the gap in knowledge and technical skills, but above all it can automate the creation of misinformation, through "fake news", by using them as a particular vehicle. The simplest example comes from the so-called "spear phishing", through which machine learning algorithms can automate the collection of information on potential victims [18]. The algorithms allow us to take advantage of the asymmetry of knowledge mentioned above.
Working on the data available on the internet, AI algorithms can identify less experienced users and distinguish them from those who surely know what spear phishing is. The first ones are certainly good targets and potential victims of a spear phishing campaign. The shortness and simplicity of the language utilized in some social media have already made it possible to use algorithms, called "bots", to manipulate information: the Syrian war and the US elections in 2016 seem to have highlighted this. Today bots are still driven by people but recent studies have shown that a bot has a good chance of looking "human" on Twitter [20]. Today, the last frontier seems to be represented by the so called "deep fakes", deep learning algorithms capable of creating fake photos or videos that are increasingly realistic (Figure 3). The Cassandras already talk of "reality under attack" and invoke future Voight-Kampff tests [21], but even here we are overestimating the present and underestimating the future of AI. It wouldn’t be the first time.

Fig. 3: Deep fakes
Acknowledgments. An Italian version of this article has been published in [22]. The authors thank “Associazione Italiana per la Sicurezza Informatica” for permission to reuse the contents.
References
[1] R. Brooks, The Seven Deadly Sins of AI Predictions, MIT Technology Review, Nov./Dec. 2017.
[2] https://obamawhitehouse.archives.gov/sites/default/files/whitehouse_files/microsites/ostp/NSTC/preparing_for_the_future_of_ai.pdf
[3] https://arxiv.org/pdf/1606.05718v1.pdf
[4] https://whatis.techtarget.com/definition/moonshot
[5] https://www.travelchinacheaper.com/best-voice-translation-apps-for-china
[6] https://ec.europa.eu/digital-single-market/en/artificial-intelligence
[7] T. Dutton, An Overview of National AI Strategies, June 2018, https://medium.com
[8] https://www.consorzio-cini.it/index.php/it/laboratori-nazionali/artificial-intelligence-and-intelligent-systems
[9] http://theconversation.com/people-dont-trust-ai-heres-how-we-can-change-that-87129
[10] https://ec.europa.eu/futurium/en/system/files/ged/ai_hleg_draft_ethics_guidelines_18_december.pdf
[11] https://www.darpa.mil/program/explainable-artificial-intelligence
[12] M. Melis, D. Maiorca, B. Biggio, G. Giacinto, and F. Roli, Explaining Black-box Android Malware Detection, 26th European Signal Processing Conference (EUSIPCO '18) 2018.
[13] https://it.wikipedia.org/wiki/Signature_based_intrusion_detection_system
[14] B. Biggio and F. Roli, Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning, Pattern Recognition, vol 2018.
[15] https://www.pluribus-one.it/research/sec-ml/sec-ml-research-area
[16] https://futureoflife.org/background/existential-risk/
[17] https://www.edge.org/response-detail/26057
[18] TM. Brundage, et al., The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, Feb. 2018. https://arxiv.org/pdf/1802.07228.pdf.
[19] http://www.difesaonline.it/evidenza/approfondimenti/campagne-di-manipolazione-dellinformazione-quando-la-difesa-fa-il-gioco
[20] https://www.blackhat.com/docs/us-16/materials/us-16-Seymour-Tully-Weaponizing-Data-Science-For-Social-Engineering-Automated-E2E-Spear-Phishing-On-Twitter-wp.pdf
[21] https://www.youtube.com/watch?v=Umc9ezAyJv0
[22] F. Roli, Intelligenza Artificiale: il Buono, il Brutto, il Cattivo, Rapporto Clusit 2019 sulla Sicurezza ICT in Italia, 2019 (in Italian)


