")
")
Secure ML Research
Research area on the Security of Machine Learning
Secure ML Research Tutorial: Wild Patterns Secure ML Library
Secure ML Research Tutorial: Wild Patterns Secure ML Library
Machine-learning and data-driven AI technologies have reported impressive performances in computer vision and security-sensitive tasks. From self-driving cars and robot-vision systems to spam and malware detection tools, such technologies have become pervasive.
However, when deployed in the wild, these technologies may encounter adversarial conditions or unexpected variations of the input data. Understanding their security properties and designing suitable countermeasures has thus become a timely and relevant open research challenge towards the development of safe AI systems.
Interviews to our team members on security of AI and Machine Learning algorithms:
July 8, 2019: BBC News, AI pilot 'sees' runway and lands automatically
April 24, 2019: New Scientist, Machine mind hack: The new threat that could scupper the AI revolution
March 3, 2019: El Pais, La guerra de los robots: la salvación antes de la era ‘fake’
February 2, 2019: The Register, Fool ML once, shame on you. Fool ML twice, shame on... the AI dev?
January 3, 2019: Bloomberg News, Artificial Intelligence Vs. the Hackers
April 29, 2018: WIRED, AI can help cybersecurity - if it can fight through the hypeJuly 27, 2020: WIRED, Facebook’s ‘Red Team’ Hacks Its Own AI Programs
May 11, 2020: WIRED, This ugly t-shirt makes you invisible to facial recognition tech
November 10, 2019: The New York Times, Building a World Where Data Privacy Exists OnlineJuly 8, 2019: BBC News, AI pilot 'sees' runway and lands automatically
April 24, 2019: New Scientist, Machine mind hack: The new threat that could scupper the AI revolution
March 3, 2019: El Pais, La guerra de los robots: la salvación antes de la era ‘fake’
February 2, 2019: The Register, Fool ML once, shame on you. Fool ML twice, shame on... the AI dev?
January 3, 2019: Bloomberg News, Artificial Intelligence Vs. the Hackers
March 9, 2018: WIRED, AI has a hallucination problem that’s proving tough to fix
Read more articles...
Read more articles...
Our research team has been among the first to:
- show that machine-learning algorithms are vulnerable to gradient-based adversarial manipulations of the input data, both at test time (evasion attacks) and at training time (poisoning attacks);
- derive a systematic framework for security evaluation of learning algorithms; and
- develop suitable countermeasures for improving their security.
Evasion attacks (also recently referred to as adversarial examples) consist of manipulating input data to evade a trained classifier at test time. These include, for instance, manipulation of malware code to have the corresponding sample misclassified as legitimate, or manipulation of images to mislead object recognition.
Our research members have been among the first to demonstrate these attacks against well-known machine-learning algorithms, including support vector machines and neural networks (Biggio et al., 2013). Evasion attacks have been independently derived in the area of deep learning and computer vision later (C. Szegedy et al., 2014), under the name of adversarial examples, namely, images that can be misclassified by deep-learning algorithms while being only imperceptibly distorted.
Our research members have been among the first to demonstrate these attacks against well-known machine-learning algorithms, including support vector machines and neural networks (Biggio et al., 2013). Evasion attacks have been independently derived in the area of deep learning and computer vision later (C. Szegedy et al., 2014), under the name of adversarial examples, namely, images that can be misclassified by deep-learning algorithms while being only imperceptibly distorted.
Poisoning attacks are subtler. Their goal is to mislead the learning algorithm during the training phase by manipulating only a small fraction of the training data, in order to significantly increase the number of misclassified samples at test time, causing a denial of service. These attacks require access to the training data used to learn the classification algorithm, which is possible in some application-specific contexts.
We demonstrated poisoning attacks against support vector machines (Biggio et al., 2012), then against LASSO, ridge and elastic-net regression (Xiao et al., 2015; Jagielski et al., 2018), and more recently against neural networks and deep-learning algorithms (L. Muñoz-González et al., 2017).
We demonstrated poisoning attacks against support vector machines (Biggio et al., 2012), then against LASSO, ridge and elastic-net regression (Xiao et al., 2015; Jagielski et al., 2018), and more recently against neural networks and deep-learning algorithms (L. Muñoz-González et al., 2017).
Read the full story on our recent paper "Wild Patterns: Ten Years after the Rise of Adversarial Machine Learning".
Timeline of Learning Security
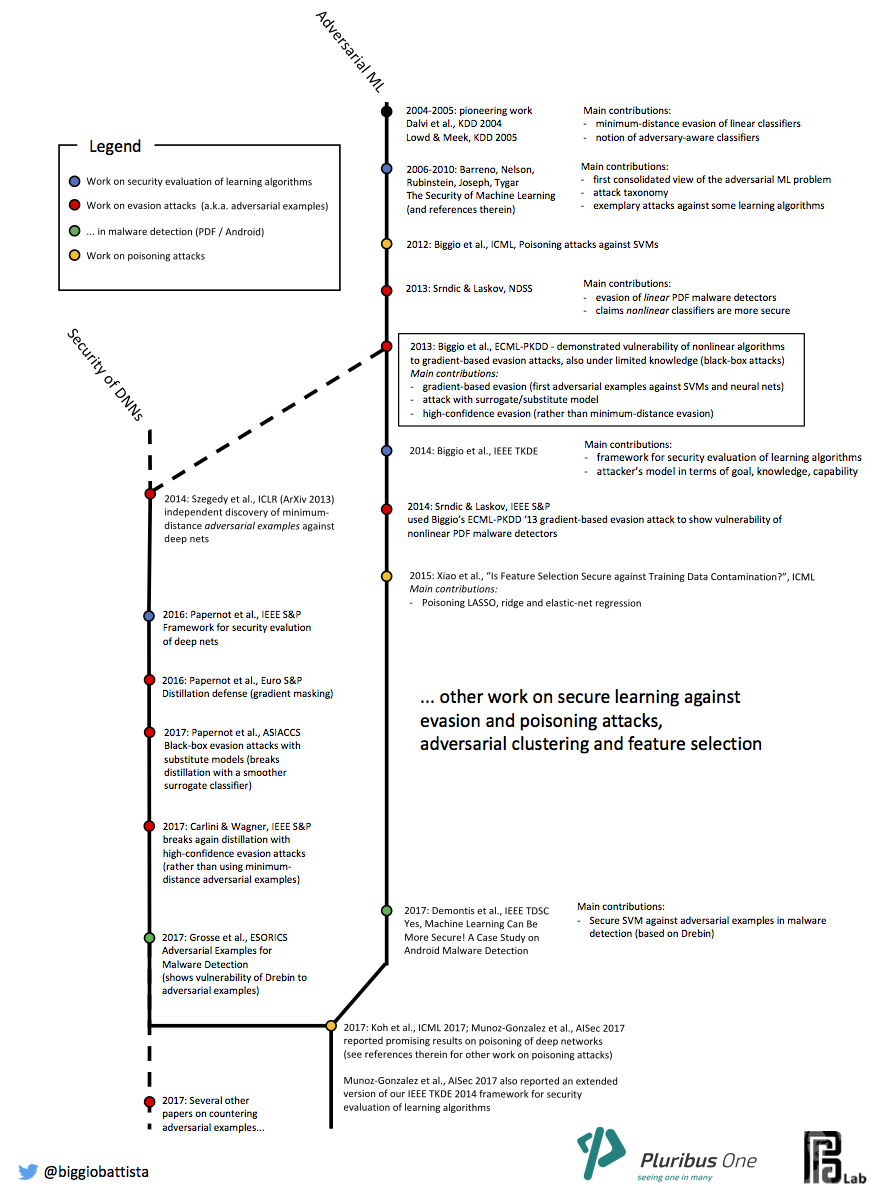
Relevant Publications
- Poisoning Attacks against Support Vector Machines, B. Biggio, B. Nelson, P. Laskov. In ICML 2012
- Evasion Attacks against Machine Learning at Test Time, B. Biggio, I. Corona, D. Maiorca, B. Nelson, N. Šrndić, P. Laskov, G. Giacinto, F. Roli. In ECML-PKDD 2013
- Security Evaluation of Pattern Classifiers under Attack, B. Biggio, G. Fumera, F. Roli. In IEEE TKDE 2014
- Is Feature Selection Secure against Training Data Poisoning?, H. Xiao, B. Biggio, G. Brown, G. Fumera, C. Eckert, F. Roli. In ICML
- Is Deep Learning Safe for Robot Vision? Adversarial Examples against the iCub Humanoid, M. Melis, A. Demontis, B. Biggio, G. Brown, G. Fumera, F. Roli. In 2017 ICCV Workshop ViPAR
- Towards Poisoning of Deep Learning Algorithms with Back-gradient Optimization, L. Muñoz-González, B. Biggio, A. Demontis, A. Paudice, V. Wongrassamee, E. C. Lupu, F. Roli. In AISec 2017
- Yes, Machine Learning Can Be More Secure! A Case Study on Android Malware Detection, A. Demontis, M. Melis, B. Biggio, D. Maiorca, D. Arp, K. Rieck, I. Corona, G. Giacinto, F. Roli. In IEEE TDSC 2017
- Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning, B. Biggio, F. Roli. In Pattern Recognition (under review)
Relevant Lectures

The sad thing about artificial intelligence is that it lacks artifice and therefore intelligence
Jean Baudrillard, Sociologist


